隨著數(shù)字化轉(zhuǎn)型的深入,企業(yè)信息系統(tǒng)正朝著松耦合、高可用的微服務(wù)架構(gòu)演進(jìn)。在這一進(jìn)程中,服務(wù)間的可靠、高效通信成為關(guān)鍵。Apache Kafka,作為一個(gè)分布式的流處理平臺(tái)與消息中間件,憑借其獨(dú)特的高性能設(shè)計(jì),已成為微服務(wù)集成與異步通信的核心基礎(chǔ)設(shè)施。本文將探討Kafka的高性能設(shè)計(jì)哲學(xué),及其在構(gòu)建現(xiàn)代化、高性能信息系統(tǒng)集成服務(wù)中的核心作用。
一、Kafka高性能設(shè)計(jì)的核心支柱
Kafka的高性能并非偶然,而是源于其精心的架構(gòu)設(shè)計(jì),主要集中在以下幾個(gè)方面:
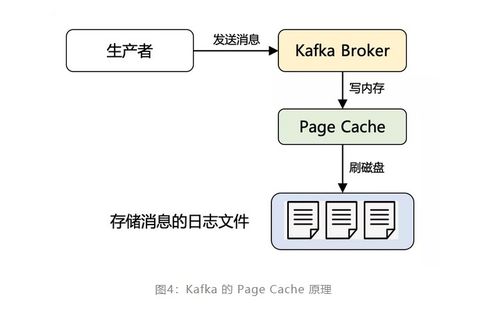
- 順序磁盤I/O與零拷貝技術(shù):與傳統(tǒng)數(shù)據(jù)庫的隨機(jī)讀寫不同,Kafka將消息持久化到磁盤時(shí)采用順序追加寫入的方式,其速度甚至可以超過內(nèi)存的隨機(jī)讀寫。在消費(fèi)者讀取時(shí),Kafka利用操作系統(tǒng)的零拷貝(Zero-copy) 技術(shù),將磁盤文件的數(shù)據(jù)直接通過網(wǎng)絡(luò)發(fā)送給消費(fèi)者,避免了內(nèi)核緩沖區(qū)與用戶緩沖區(qū)之間的多次拷貝,極大降低了CPU開銷和上下文切換。
- 分區(qū)(Partition)與并行機(jī)制:Topic在物理上被劃分為多個(gè)分區(qū),分布在不同的Broker上。這種設(shè)計(jì)實(shí)現(xiàn)了數(shù)據(jù)的水平拆分和負(fù)載均衡。生產(chǎn)者和消費(fèi)者可以并行地向多個(gè)分區(qū)讀寫數(shù)據(jù),從而線性提升系統(tǒng)的整體吞吐量。這是支撐海量數(shù)據(jù)流處理的基礎(chǔ)。
- 基于日志的持久化與批處理:Kafka將所有消息以僅追加(append-only)的日志形式存儲(chǔ)。生產(chǎn)者發(fā)送消息時(shí),并非每條消息都立即觸發(fā)網(wǎng)絡(luò)和磁盤I/O,而是會(huì)先在客戶端進(jìn)行批量壓縮,積累到一定大小或時(shí)間后再批量發(fā)送。這種批處理機(jī)制顯著減少了網(wǎng)絡(luò)往返和I/O操作次數(shù)。
- 高效的消費(fèi)者組模型:Kafka的消費(fèi)者采用“拉取(Pull)”模式,可以自主控制消費(fèi)速率和時(shí)機(jī)。消費(fèi)者組(Consumer Group)機(jī)制使得同一組內(nèi)的消費(fèi)者可以共同消費(fèi)一個(gè)Topic的多個(gè)分區(qū),實(shí)現(xiàn)消費(fèi)能力的彈性伸縮和高可用,避免了消息隊(duì)列常見的“廣播”帶來的性能瓶頸。
二、在信息系統(tǒng)集成服務(wù)中的典型應(yīng)用場(chǎng)景
在微服務(wù)架構(gòu)的信息系統(tǒng)集成中,Kafka扮演著“中樞神經(jīng)系統(tǒng)”的角色:
- 服務(wù)解耦與異步通信:訂單服務(wù)在創(chuàng)建訂單后,只需將“訂單創(chuàng)建”事件發(fā)布到Kafka的
order-eventsTopic,而庫存服務(wù)、物流服務(wù)、風(fēng)控服務(wù)等作為獨(dú)立的消費(fèi)者,異步地訂閱并處理該事件。服務(wù)間無需直接HTTP/RPC調(diào)用,實(shí)現(xiàn)了徹底解耦,提高了系統(tǒng)的整體彈性和可維護(hù)性。
- 事件溯源與數(shù)據(jù)流管道:Kafka可以作為所有領(lǐng)域事件的持久化存儲(chǔ),構(gòu)建事件溯源(Event Sourcing) 系統(tǒng)。所有改變系統(tǒng)狀態(tài)的事件都被順序記錄,為審計(jì)、數(shù)據(jù)回放和構(gòu)建新的數(shù)據(jù)視圖提供了可能。Kafka Connect可以方便地將數(shù)據(jù)從數(shù)據(jù)庫、日志文件導(dǎo)入Kafka,或從Kafka導(dǎo)出到數(shù)據(jù)倉庫(如Hadoop、ES),構(gòu)建實(shí)時(shí)數(shù)據(jù)管道。
- 流處理與實(shí)時(shí)分析:結(jié)合Kafka Streams或Flink等流處理框架,可以對(duì)流經(jīng)Kafka的數(shù)據(jù)進(jìn)行實(shí)時(shí)處理。例如,在用戶行為分析系統(tǒng)中,實(shí)時(shí)計(jì)算點(diǎn)擊率、統(tǒng)計(jì)在線人數(shù);在風(fēng)控系統(tǒng)中,實(shí)時(shí)分析交易流水,識(shí)別異常模式。
三、構(gòu)建高性能集成服務(wù)的實(shí)踐要點(diǎn)
要充分發(fā)揮Kafka的性能優(yōu)勢(shì),在系統(tǒng)集成設(shè)計(jì)中需注意:
- 合理的Topic與分區(qū)規(guī)劃:根據(jù)業(yè)務(wù)域和數(shù)據(jù)吞吐量設(shè)計(jì)Topic,避免“大雜燴”。分區(qū)數(shù)是Kafka并行度的上限,需要根據(jù)預(yù)期的消費(fèi)者數(shù)量和吞吐量進(jìn)行合理設(shè)置,并預(yù)留擴(kuò)容空間。
- 優(yōu)化生產(chǎn)與消費(fèi)配置:生產(chǎn)者端合理配置
batch.size和linger.ms以優(yōu)化批處理;根據(jù)對(duì)可靠性的要求選擇acks配置(如acks=1在性能與可靠性間取得平衡)。消費(fèi)者端注意控制fetch.min.bytes以提升拉取效率,并做好偏移量管理。 - 保障高可用與監(jiān)控:Kafka集群本身應(yīng)部署多副本(Replication),確保Broker故障時(shí)數(shù)據(jù)不丟失、服務(wù)不間斷。必須建立完善的監(jiān)控體系,關(guān)注集群吞吐量、網(wǎng)絡(luò)IO、磁盤使用率、消費(fèi)延遲(Lag)等關(guān)鍵指標(biāo)。
- 端到端的語義保障:根據(jù)業(yè)務(wù)需求,明確消息傳遞的語義(如至多一次、至少一次、恰好一次),并通過冪等生產(chǎn)者、事務(wù)API等機(jī)制予以實(shí)現(xiàn)。
###
Apache Kafka通過其以吞吐量和擴(kuò)展性為核心的設(shè)計(jì),為微服務(wù)架構(gòu)提供了強(qiáng)大的異步通信骨干。在復(fù)雜的信息系統(tǒng)集成服務(wù)中,它不僅是消息傳遞的管道,更是實(shí)時(shí)數(shù)據(jù)流的統(tǒng)一平臺(tái)。深入理解其高性能原理,并在此基礎(chǔ)上進(jìn)行合理的架構(gòu)設(shè)計(jì)與運(yùn)維,是構(gòu)建敏捷、可靠、能夠應(yīng)對(duì)海量數(shù)據(jù)挑戰(zhàn)的現(xiàn)代信息系統(tǒng)的關(guān)鍵所在。將Kafka融入系統(tǒng)集成藍(lán)圖,意味著選擇了面向未來流式數(shù)據(jù)世界的高性能路徑。